News
DOSSIER : SYNTHÈSE DE LA JOURNÉE SCIENTIFIQUE ET TECHNIQUE DE LA COMMISSION 3AF STRUCTURES
Article paru dans la Lettre 3AF N°1-2024
Application aux Structures Aérospatiales des Avancées Récentes en Intelligence Artificielle et Science des Données - Duplex SAFRAN Tech (Palaiseau) - AIRBUS SAS (Toulouse) - 25 avril 2023
Par Stéphane Grihon (Airbus), Bruno Mahieux (SAFRAN) et Éric Deletombe (ONERA)
OBJECTIFS
Il est devenu courant depuis l’avènement du phénomène « Big Data » de déclarer que nos données sont une mine insuffisamment exploitée. Comment se décline ce constat dans le cadre du cycle de vie des structures aéronautiques et spatiales ? En effet, le cycle de vie des structures aérospatiales constitue un champ d’application indubitable en Sciences des Données, tant une structure aérospatiale peut être abordée comme un système complexe qui nécessite à différentes échelles des méthodes d’analyse relevant soit de la simulation, soit de l’empirique et générant au total des quantités massives de données. De plus, la nécessité du suivi de chaque structure en qualité et en maintenance opérationnelle entraîne un flot de données continu provenant de la fabrication et de l’exploitation. Tous les éléments sont donc réunis pour fournir un contexte d’application fructueux pour les sciences des données.
En phase de conception l’aspect périodique et le haut taux de réutilisation des structures pour aéronefs et systèmes spatiaux dérivés (variantes de masse par exemple) autorisent à préparer des modèles basés sur les données pour accélérer les calculs de conception jusqu’à la certification et réduire les temps de cycle et de mise sur le marché. Les approches traditionnelles de calibration de modèles sur base expérimentale peuvent être également traitées avantageusement par l’usage de techniques d’assimilation des données utilisant des méta-modèles à la jonction entre la simulation et l’expérimental. L’ascension récente des modèles physiquement informés s’appuyant essentiellement sur des réseaux de neurones artificiels est une voie prometteuse d’accélération des simulations structurales et se prête bien à des approches hybrides simulation/expérimental. Ces deux leviers permettent d’améliorer la représentativité des modèles et de réduire les conservatismes sans dégrader les niveaux de sécurité. Il faut toutefois remarquer le déséquilibre à gérer entre les données expérimentales plus coûteuses à obtenir et plus rares et les données de simulation plus faciles à générer et plus nombreuses. Quoiqu’il en soit, les méthodes frugales nécessitant peu de données restent un axe à privilégier pour minimiser à la fois l’effort de simulation et l’effort expérimental.
Enfin, les solutions de conception, de réparation ou de maintenance se trouvent souvent dans l’historique des données qui restent à analyser. C’est là le moyen de réduire à nouveau les temps de cycle et de réponse au client. L’analyse des bases de données opérationnelles permet de raffiner les conditions de conception et d’adapter les exigences de certification donnant lieu à un produit plus optimisé qui conserve tous les requis de sécurité. Quant au suivi opérationnel, il permet de raffiner les hypothèses de modélisation et d’adapter les programmes de maintenance aux besoins de chaque opérateur, potentiellement individualisé pour chaque système, ce qui apporte un gain significatif dans l’exploitation opérationnelle. A noter que dans le cadre de la surveillance en continu de la santé des structures, il est nécessaire d’enrichir les modèles pour prendre en compte l’évolution des propriétés et des performances (apprentissage augmenté) et autoriser à la fois diagnostic et pronostic.
Tous ces sujets sont autant d’exemples de cas d’usage des Sciences des Données en émergence chez la plupart des concepteurs et opérateurs du secteur aérospatial, avec le soutien des laboratoires de recherche. Ils témoignent de la vitalité du domaine que cette journée 3AF propose d’explorer en apportant le nécessaire regard critique sur leur potentiel et leur maturité, et en donnant les perspectives d’évolution à court et moyen terme.
La conférence plénière de cette journée, intitulée « Données et intelligence augmentée par la physique pour de nouvelles démarches prédictives » fut donnée par Pierre Ladevèze (LMPS Paris-Saclay) et Francesco Chinesta (Arts & Métiers Paris). Elle avait pour but de restituer la science des données dans le contexte de la simulation pour l’ingénierie, de donner des exemples d’applications et d’adresser quelques recommandations.
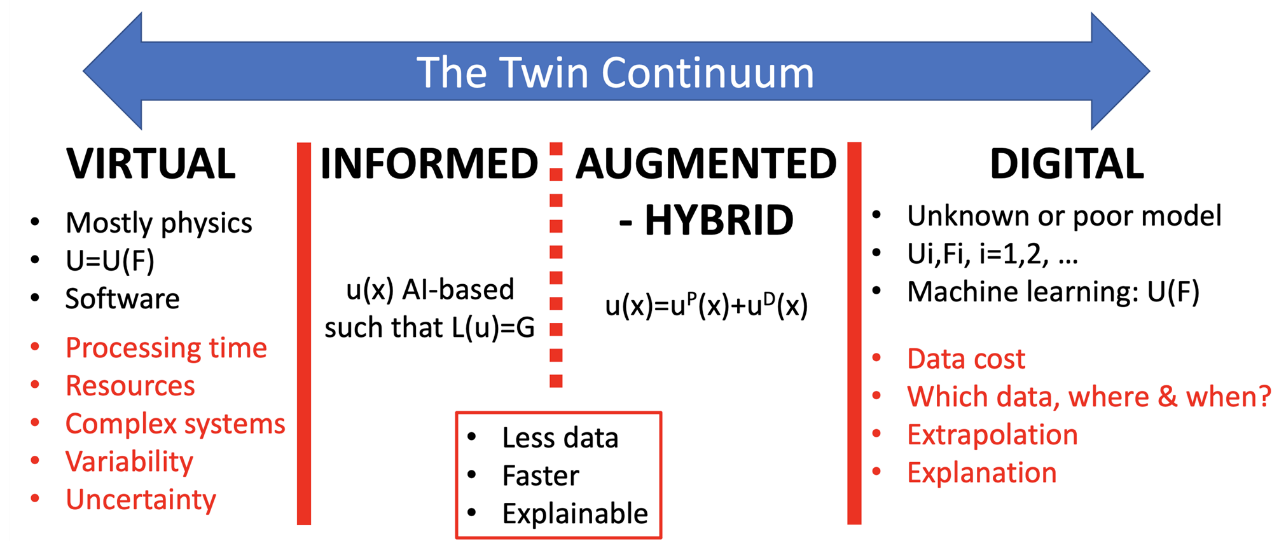
Fig.1 Le contexte actuel de la simulation intégrant les apports des sciences de la donnée
Le contexte fut d’abord introduit en faisant remarquer une nette orientation de la simulation pour l’ingénierie au 21ème siècle, de bout en bout, couvrant le cycle de vie de la conception à l’opérationnel, du composant au système de système, grâce précisément à la science des données et se déclinant suivant la part d’utilisation de la donnée en 4 champs : la simulation physique, physiquement informée, hybride et purement orientée par la donnée.
Les différentes méthodes d’analyse/de traitement furent alors décrites, et la diversité de la typologie des données (listes, images, graphes, courbes, séries temporelles) s’appuyant sur de la simulation ou des mesures rappelée, en soulignant l’importance de la représentativité et de la complétude de ces données. Furent ensuite évoquées les techniques de réduction de dimension et en particulier les auto-encodeurs qui permettent de dégager des variables latentes pour un modèle portant sur un espace d’entrées de grande dimension. Enfin, un inventaire des différents modèles d’apprentissage machine fut dressé, et un encouragement à commencer d’abord par des modèles simples comme les polynômes, donné.
Pour le champ d’application aérospatial, aux contraintes de sécurité particulièrement sévères, un requis attendu des résultats des analyses/traitements concerne le respect des principes de la physique et des équations de comportement scientifiquement établies (ne pouvant qu’être enrichies par la connaissance du comportement expérimental) : en conséquence, un cadre hybride – dans lequel la construction du modèle est pilotée par une fonction hybride mélangeant la distance aux équations de comportement et à la mesure – s’impose, garantissant la pertinence d’emploi des approches purement mathématiques de la science de la donnée.
Dans le domaine applicatif, un cas d’école fut d’abord discuté (poutre en flexion) pour montrer la difficulté à généraliser des modèles orientés par la donnée : il est d’abord montré qu’une approche purement
« données », empirique, qui nous ramènerait à l’époque de Galilée car ignorant la connaissance moderne des comportements physiques, est clairement à proscrire. Une seconde application, concernant la plateforme de vibration du CEA (pour simulations sismiques), fut ensuite présentée : l’enjeu de l’exercice est de détecter et modéliser l’endommagement dans les liaisons structurales. Un modèle grossier est utilisé, avec son lot de paramètres, et alimenté par des mesures. L’erreur de modélisation et la distance aux données sont minimisées en utilisant la technique de pondération de Morozov (de façon à ce que l’erreur de modélisation soit de même niveau que l’erreur de mesure). Une régularisation de Tikhonov est utilisée. Le contrôle se fait par un filtre de Kalman en utilisant les 3 premières fréquences propres de la plateforme, ce qui donne par nature accès à des intervalles de confiance. Les résultats ainsi obtenus montrent que les pics de réponse sont correctement représentés. D’autres applications furent présentées dans le domaine de l’identification de lois de comportement pour les matériaux, où il s’avère qu’une approche pilotée par la donnée (data-driven) permet de construire des modèles, à partir d’une base empirique, capables de donner des résultats fidèles aux données, avec néanmoins - en l’absence (et parfois même en présence) de fondement physique - des difficultés à extrapoler hors du domaine ayant servi à la construction du modèle. Un premier exemple concernait une loi d’endommagement matériau avec des comportements différents en traction-compression, mesurés par fibre optique, pour laquelle différentes méthodes visant à forcer la convexité de la fonction énergie (enveloppe de fonctions linéaires, méthodes à noyau, réseau de neurone à architecture particulière) étaient comparées. Un deuxième exemple s’intéressait à un comportement élasto-plastique complexe où devaient être identifiées des variables cachées. Enfin, un autre champ d’application fut évoqué, qui concernait le diagnostic et le pronostic de la santé des structures : un exemple de projet de génie civil fut présenté, qui s’intéressait à l’analyse de la santé structurale d’un pont, pour laquelle un drone était utilisé afin de compenser la difficulté d’équiper l’ensemble de la structure avec des capteurs, ce qui permettait d’aller chercher et acquérir la donnée « au bon endroit » en utilisant différents moyens. Le diagnostic est alors établi en temps réel grâce à un réseau de neurones, par écart au modèle mécanique, sur la base d’un plan d'expérience contenant des millions de cas de dommage simulés, ce qui permet au drone (à son opérateur, équipé de lunettes de réalité virtuelle pour « voir » comme le drone) de détecter des dommages sur tuyaux lors de l’inspection.
En conclusion, les principales étapes préconisées pour l’établissement d’une démarche fiable et prédictive d’analyse mécanique, fondées sur les données, sont rappelées : (1) poser le problème mécanique, (2) questionner les données disponibles : lesquelles, où, quand, utilité, accessibilité, (3) dresser l’état des connaissances préalables, (4) proposer une méthode de validation de la méthode/des résultats, et (5) évaluer le coût de la démarche.
La seconde intervention de la journée, intitulée
« Modèles de substitution pour le calcul des charges et des structures : validation et vérification », fut donnée par Stéphane Grihon (AIRBUS SAS), co-organisateur de la journée. L’objectif de l’exposé était de présenter les méthodes mises en place par Airbus pour faire la vérification et la validation des modèles de substitution ou “surrogate models”, plus particulièrement dans le contexte charges/analyses de structure. Un rappel de ce qu'est un modèle de substitution fut d’abord effectué : principe mathématique et intérêts industriels, ces derniers étant multiples, le plus courant étant celui d’accélérer les processus de simulation, en cherchant à limiter les étapes d’intégration et les interventions humaines. Les types d'application évoquées sont alors divers : jumeau numérique, optimisation, nouveaux services, avec un nouveau domaine en pointe de la recherche, l'hybridation.
Le contexte interne Airbus se caractérise par des projets internes avancés en termes d'implémentation dans le domaine charges/analyse en contrainte, et l’implication dans des groupes de travail internationaux (EUROCAE WG114, SAE G34) visant à construire le futur standard de certification des produits issus de l’intelligence artificielle. A noter que l’EASA participe au WG114 mais produit aussi ses propres documents (par exemple un « concept paper », comme premier document certificatoire) et monte des projets sur l’IA de confiance. Un groupe de travail interne à AIRBUS a été créé pour harmoniser ces différentes initiatives et avoir un référentiel interne de méthodes propre, pour répondre aux exigences de vérification et validation en vue de la certification. L'activité 2022 sur ce point a consisté à écrire une première version de rapport en commençant par l'évaluation de modèles, qui doit ensuite piloter l'évaluation des données. Des chapitres complémentaires ont été ajoutés sur l'explicabilité et le lien au « concept paper » de l'EASA. Des activités parallèles ont enfin été menées sur le projet pilote AIRBUS Aero2stress.
Il est rappelé que pour construire un bon modèle de substitution, les données doivent être complètes et représentatives. L'extrapolation ne fonctionne pas avec le pur pilotage par la donnée (data-driven) qui n’autorise que l’exercice d'interpolation, dans les bornes du domaine de conception. L’hybridation avec les équations de la physique, qui en est à ses premiers pas et pourrait conférer une capacité à extrapoler, n’est pas toujours applicable. On parle donc pour l’instant chez AIRBUS plus exactement de généralisation, et on se limite au périmètre du domaine des entrées ou
« Operational Design Domain ». La propriété majeure à assurer pour un modèle de substitution, sa robustesse, consiste à parer en opération toute donnée qui pourrait être mal prédite. Il faut pour cela un prédicteur d'erreur. Le domaine de conception généralement continu ne pouvant jamais être connu dans sa totalité, la caractérisation de cette erreur est toujours probabiliste : on cherche à montrer qu’elle reste inférieure à ε pour une probabilité supérieure à 1 - δ (niveau de risque), ε et δ devant être bien spécifiés au début de l’étude. La généralisation proposée par AIRBUS est finalement supportée par un compromis entre biais, variance, et stabilité, qui sont des propriétés importantes (NB : mais secondaires par rapport à la robustesse).
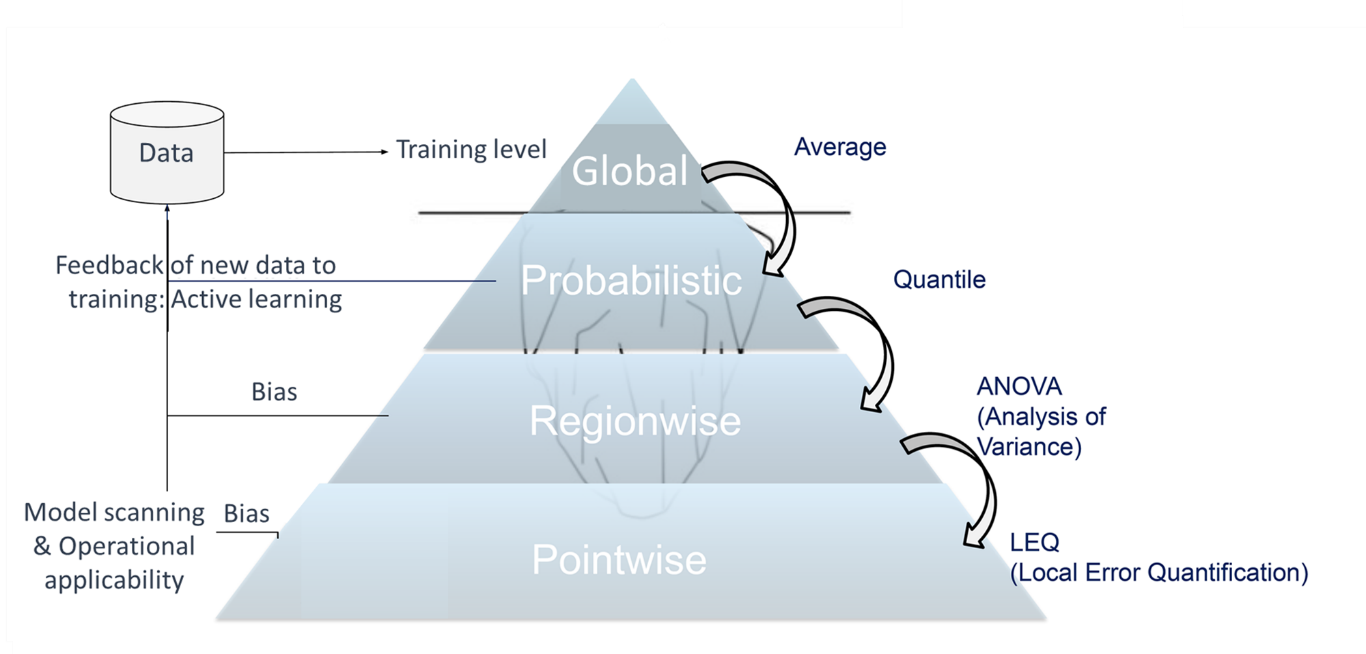
Fig.2 Approche pyramidale développée chez AIRBUS
pour la précision et la robustesse des modèles de substitution
L'approche d'Airbus est, dans un sens, plus exigeante que ce qui apparaît dans les standards en cours d’élaboration. Elle propose une analyse de l'erreur pyramidale qui part d'un niveau global d'erreur qui correspond en général à la fonction de perte minimisée lors de l'apprentissage, puis qui analyse l’erreur par région et finalement ponctuellement, produisant par la même occasion un estimateur qui permet d'assurer la robustesse en opérations et doit être déployé avec le modèle. À chaque étage de la pyramide, il peut se produire une itération si la distribution de l'erreur n'est pas satisfaisante : soit le modèle est remis en cause (réglage des hyperparamètres), soit ce sont les données (échantillonnage adaptatif, apprentissage actif).
La méthode développée au stade ponctuel « Local Error Quantification » offre le moyen d’évaluer l’erreur en tout nouveau point et permet ainsi par son utilisation en opération de garantir la robustesse du modèle. Si le niveau d’erreur prédite est au delà de ce qui a été spécifié alors le modèle n’est pas utilisé et un back-up doit être employé (la simulation d’origine par exemple).
En conclusion, il est rapporté que les derniers travaux menés chez AIRBUS SAS ont permis de travailler sur l'évaluation des données avec un regard critique, car c'est une vérification indirecte qui sera faite par la qualité du modèle. La traçabilité est un aspect majeur du processus, étant donnée la dépendance des modèles aux données. Si la vérification des données en opérations est essentielle, l'explicabilité n'est quant à elle pas un point majeur. Enfin, les activités à venir viseront à consolider ce travail et l'appliquer plus particulièrement au projet HALO (HArd Landing Optimization).
La troisième présentation du séminaire, était intitulée « Prise en compte de la variabilité dans la conception : exemples industriels », par Frédéric Bonnet, Christophe Colette, Elisabeth Ostoja-Kuczynski, Gérald Senger (SAFRAN Helicopter Engines). Elle visait à montrer, à l’aide de cas d’école et d’exemples concrets, comment s’opère la gestion des incertitudes en lien avec la fabrication (tolérancement), pour les structures de moteurs d’hélicoptères. Ces moteurs restent en opération pendant des dizaines d'années, ils fonctionnent pendant des milliers d'heures, et sont en production pendant 30 à 40 ans. Ils sont naturellement soumis à la variabilité et, de plus, à un environnement changeant en termes de fournisseurs, opérateurs, machines-outils, etc.
Pour expliciter les raisons/les objectifs d’une prise en compte de la variabilité en conception, l’exemple du jeu résultant d’un empilement de pièces fut utilisé (traité simplement en une dimension). Une première approche - l’utilisation d’amortissement statistique – s’avère ne pas suffire car elle peut amener à obtenir des couples définition/fabrication non robustes au changement, par exemple lors du passage à une machine plus précise qui déplace la conception hors de l’espace de variabilité originel : des pièces unitaires conformes à la conception, néanmoins non conformes à l'assemblage après relaxation de l'exigence de centrage. Le second exemple évoqué, celui d’une roue de turbine à pales rapportées, s’avère assez proche du cas d’école précédent : si le jeu inter-pales est trop important, se pose un problème de performance, s’il est trop faible, c’est la montabilité qui est impactée. Un compromis est donc à trouver : pour cela, se donner la possibilité d’avoir des pales et des distances non uniformes permet d’élargir le domaine de conception.
Concernant cette fois la façon de prendre en compte la variabilité en conception, un exemple multidimensionnel (sur deux variables) fut ensuite discuté : la possibilité étant offerte avec une nouvelle machine de satisfaire plus rigoureusement un intervalle de tolérance de fabrication, une question fonctionnelle s’en trouvait impactée, la solution la plus évidente pour résoudre le problème (recentrer l'intervalle de tolérance) s’avérant infaisable : ceci illustrant l’importance/la nécessité de prendre en compte dans un problème multi-variables, les corrélations et les restrictions entre variables. Fut ensuite expliqué que les approches théoriques ou basées sur des solveurs numériques étaient alors à utiliser avec prudence : avant de ce faire, il fallait avoir identifié au préalable les bons paramètres et leur distribution, sous peine de faire des erreurs d’interprétation ou de fournir des résultats erronés. Ainsi, l’hypothèse « normale centrée » pouvait donner des résultats très éloignés de ceux obtenus avec une distribution réelle, constatée. Un autre exemple industriel, celui du brochage d'alvéoles de turbine, fut encore présenté, pour lequel la variabilité de certains paramètres était évolutive dans le temps (écarts-types court terme et long terme différents), à cause de l’usure à l'usage de l'outil de brochage : la façon de concevoir devait être revue car les optima étaient décalés à cause de la prise en compte de ces incertitudes, un critère de fiabilité interférant avec un critère de performance.
Au final, il fut rappelé qu’il fallait naturellement tenir compte de l’ensemble des sources de variabilité si on voulait un résultat pertinent (matériaux, fabrication, montage, usage, mesures, etc.), et que la collecte de toutes les données nécessaires, signifiait/requérait l’implémentation d’un jumeau numérique (objectif pour l’usine 4.0). En ce qui concerne la caractérisation de la variabilité et son exploitation, ce jumeau numérique permet d’avoir “la carte vitale” des pièces, en collectant 3 types de données : dimensions produit, variation temporelle des paramètres du procédé d'élaboration et le contexte (N° outillage, réglages sur machines, lot de fabrication, …). Ceci sans oublier les points majeurs pour l’implémentation d’un jumeau numérique que sont l’accessibilité de la donnée et la cybersécurité.
In fine, la stratégie retenue par SAFRAN Hélicoptères ne vise pas à fournir la donnée uniquement à des analystes (qui interviendront sur des traitements pointus, comme l’apprentissage machine), mais à tous les acteurs concernés, en formant largement la population à l’utilisation des outils de base de la collecte et de l’analyse statistique des données. Un dernier exemple fut ainsi présenté, qui concernait la fabrication de pieds de sapin des pales de turbine, fabrication complexe qui implique le réglage de 35 côtes, 6 volants étant utilisés par l’opérateur – doté d’une longue et solide expérience - pour ajuster les meules : une intelligence artificielle a été développée – en l’espace de moins de deux ans - pour que la machine puisse avec succès, après une phase d’apprentissage supervisée par l’opérateur, effectuer elle-même les réglages. Résultats : un temps significatif gagné sur la production des pales, des taux de rebuts divisés par 3, et un opérateur qui dirige désormais 2 machines au lieu d’une.
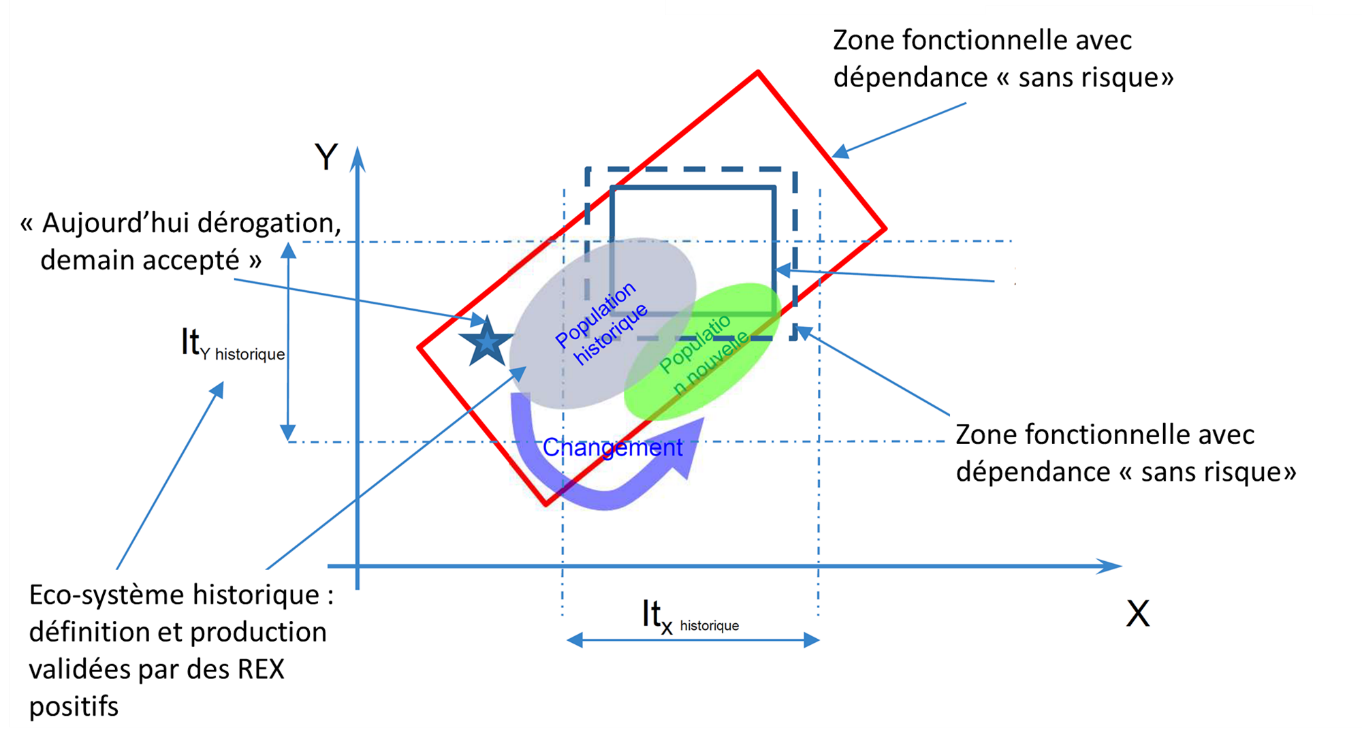
Fig.3 Prise en compte de la variabilité en conception chez SAFRAN Hélicoptères
En termes de conclusion finale, conception et fabrication sont intrinsèquement liés : d’une part, il est nécessaire de bien connaître les moyens de production pour réussir à concevoir des pièces fonctionnelles et, d’autre part, la prise en compte de la variabilité et des interdépendances modifie les façons de concevoir. Finalement, les progrès attendus dans le domaine de la prise en compte des incertitudes en conception sont liés aux moyens mathématiques, aux puissances de calculs, mais également à la montée en compétence collective dans les data-science et les statistiques.
Le quatrième exposé de la journée était intitulé « Quantification et gestion des incertitudes dans une perspective de co-design », préparé et réalisé par P. Wojtowicz et G. Capasso (AIRBUS SAS). L’objectif de cette intervention était de présenter une méthode semi-probabiliste de gestion des incertitudes qui peut être utilisée pour résoudre des problèmes pratiques à l’interface entre le monde du calcul, le monde de la conception et le monde de la production. Cette méthode évite les approches « cas-pire », qui sont trop conservatives, tout en évitant aux ingénieurs de manipuler des probabilités, ceci en utilisant des équivalents déterministes.
En guise d’introduction, il fut rappelé qu’il y a des milliers de pièces à assembler pour constituer une structure avion. Cela se fait en plusieurs étapes : mise en position, maintien, perçage, contre-perçage... Le processus est fastidieux, long et coûteux, mais il permet de bien ajuster les fixations dans leurs logements et d’assurer une bonne tenue de l'assemblage avec une faible variabilité. L’objectif affiché était ici de réduire le nombre d'étapes : plus de perçage et contre-perçage en phase d'assemblage (« as-is » : les trous sont parfaitement coaxiaux). Les trous seraient réalisés lors de la phase de fabrication de la pièce, selon une méthode dénommée « hole-to-hole » (H2H), ce qui signifie que les trous seront potentiellement désalignés (variabilité des positions), et que les diamètres des trous devront être plus larges que le diamètre nominal pour pouvoir absorber la variabilité des désalignements des trous. Ceci implique également que la répartition des efforts entre les différentes liaisons sera également non uniforme. Avec cette approche H2H, la stratégie du pire cas n’est pas réaliste et trop pénalisante, d’autant que son application à l’ensemble de l'avion voudrait qu’on empile/tienne compte de toutes les incertitudes (sur les charges, les matériaux, la température, etc.) : une approche probabiliste rigoureuse, qui permettra de réduire le conservatisme, est donc proposée.
Dans une première partie de l’exposé, fut présenté l’effet de la variabilité géométrique sur la performance structurale. Dans le cadre général, il faut ajouter le désalignement géométrique aux quantiles de propriétés matériau et d’incertitudes charges. Le risque de sous-conservatisme est à quantifier, sans traiter le cas pire en empilant des scénarios à faible probabilité. L’approche semi probabiliste s’appuie sur des ratios entre la valeur obtenue par l'approche probabiliste et la valeur obtenue par la méthode déterministe. Cela permet de prendre des marges pour garantir la satisfaction des critères probabilistes, pour cela (1) des facteurs caractérisant la dégradation des performances sont définis et utilisés pour calculer la probabilité de dépassement. Ils interviennent généralement dans les formules, et (2) les variables intrinsèques (géométrie) sont traitées. Deux cas de gestion des incertitudes peuvent alors être étudiés, selon qu’il s’agit de déterminer :
- les facteurs d'abattement sur les admissibles pour obtenir le bon niveau de probabilité. Cela correspond mathématiquement à de l'estimation de quantile, et industriellement à une analyse des surcharges,
- le facteur d'abattement et la variabilité des entrées pour obtenir le bon niveau de probabilité. Cela correspond mathématiquement à de l'optimisation basée sur la fiabilité, et industriellement à une optimisation des tolérances.
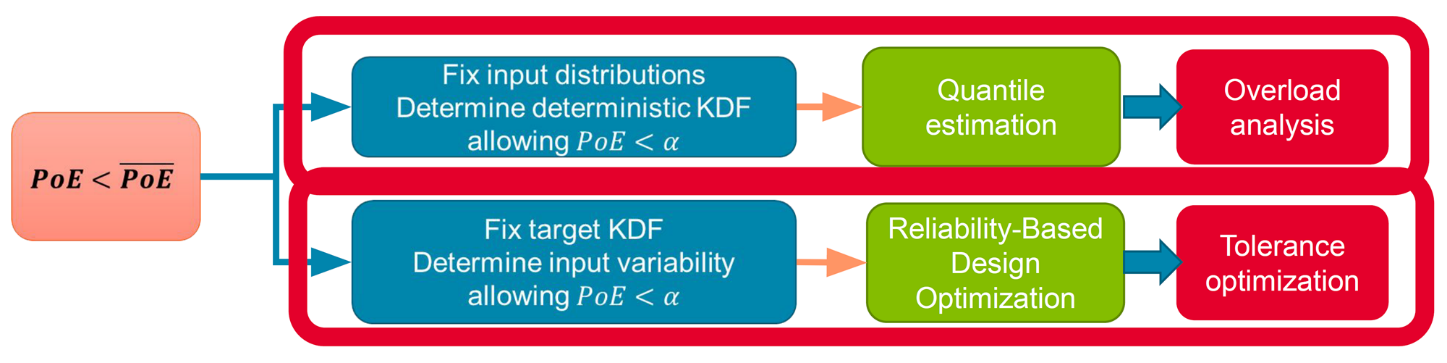
Fig.4 Deux cas fondamentaux de gestion des incertitudes en conception des structures
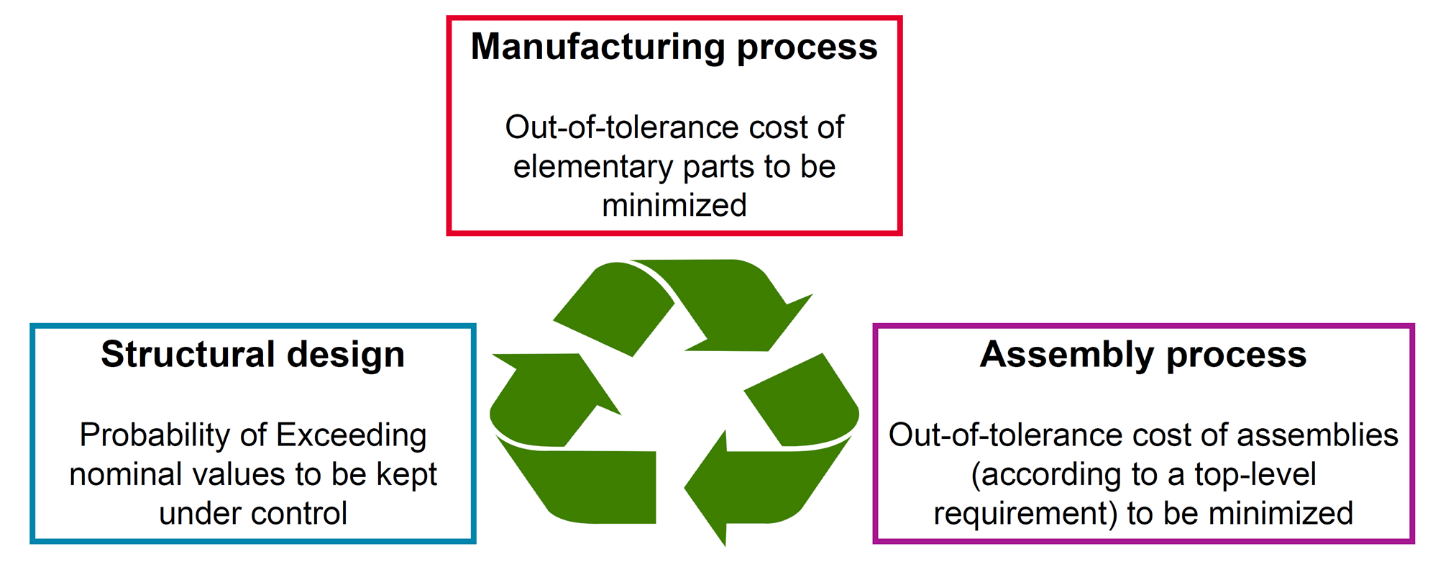
Fig.5 Cadre statistique proposé pour la co-conception (AIRBUS)
Dans le premier cas, on aboutit à une réduction significative de la surcharge en particulier pour des assemblages plus complexes. Dans le deuxième cas, cela adresse la conception structurale (pas de dépassement des valeurs admissibles), le processus de fabrication (réduire le coût lié aux pièces en dehors des tolérances), et le processus d'assemblage (réduire le coût lié aux assemblages en dehors des tolérances). On formule finalement un problème bi-objectif avec une fonction coût liée à la fabrication et une autre à l'assemblage, et on tient compte d’une contrainte sur la probabilité de dépassement (fiabilité). L'intervalle de tolérance pour la fabrication et l'assemblage ont des effets antagonistes, le bon compromis est donc à trouver. Des catalogues peuvent être fournis qui ne sont pas des solutions parfaites mais satisfont les contraintes d’optimisation de type « stress » en termes semi-probabilistes.
Les résultats d’optimisation donnent la possibilité de mettre-à-jour des bornes de troncature pour les désalignements, pour mise-à-jour par l'équipe de tolérancement. Ces bornes garantissent la satisfaction des contraintes mécaniques « stress ». Des abaques permettent de trouver le bon compromis en termes de dégradation de la performance structurale, et de décroissance des exigences qualité pour les pièces élémentaires ou l'assemblage.
En termes de conclusions et de perspectives, un cadre semi-probabiliste a été mis en place pour étudier la résistance statique des structures d’avions. Une approche de co-design impliquant la fabrication, le tolérancement et la charge (stress) a été démontrée : elle se concrétise par des abaques de facteurs de surcharge proposés et des catalogues de solutions de tolérance satisfaisant les exigences mécaniques « stress ». Un dictionnaire à 2 niveaux a été créé, soit associant le niveau de la variabilité géométrique à la performance structurale (facteur de surcharge), ou le niveau de la performance structurale à la variabilité géométrique (optimisation des contraintes de tolérance). Les perspectives pour l’application H2H sont nombreuses :
extension à la fatigue, extension aux composites, généralisation de coupons à des vraies structures aéronautiques, industrialisation du processus. Au-delà du H2H, il s’agit d’appliquer l’approche à d’autres problèmes de conception, d’introduire la notion de conception probabiliste et de supporter la roadmap de déploiement de la gestion des incertitudes.
La cinquième intervention de la journée, intitulée « Suivi de navigabilité en service pour la planification de maintenances », fut effectuée par Mickaël Duval (DGA TA). Elle visait à présenter comment la DGA en tant qu’opérateur d’armement introduit progressivement la science des données comme outil pour effectuer le suivi de flotte et adapter ses programmes de maintenance à la véritable utilisation des aéronefs. Les objectifs des travaux de la DGA, qui soutient les aéronefs des forces armées, sont d’améliorer la connaissance opérationnelle, d’augmenter la sécurité des vols, d’améliorer la gestion des flottes, d’optimiser le pas de maintenance et d’augmenter la durée de vie des appareils.
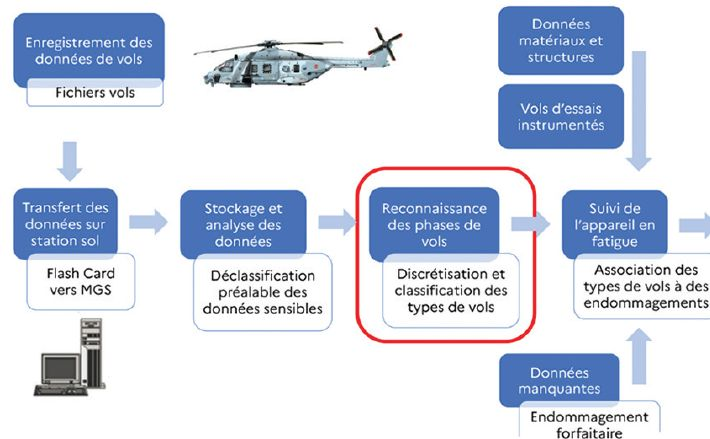
Pour le suivi en fatigue, l’aviation militaire a des spécificités par rapport à l'aviation civile, les profils de mission étant très différents : il y a de nombreux paramètres avec sources de dispersion, notamment des charges externes dues aux emports, et l’utilisation opérationnelle est différente. Illustration en fut donnée sur le cas des hélicoptères, les objectifs restant les mêmes mais venant s'y ajouter la complexité liée aux charges dynamiques hautes fréquences des machines tournantes. L’intelligence artificielle offre potentiellement les moyens d’atteindre les objectifs évoqués, en introduisant une utilisation systématique des données de vol permettant de faire un suivi individualisé de chaque appareil.
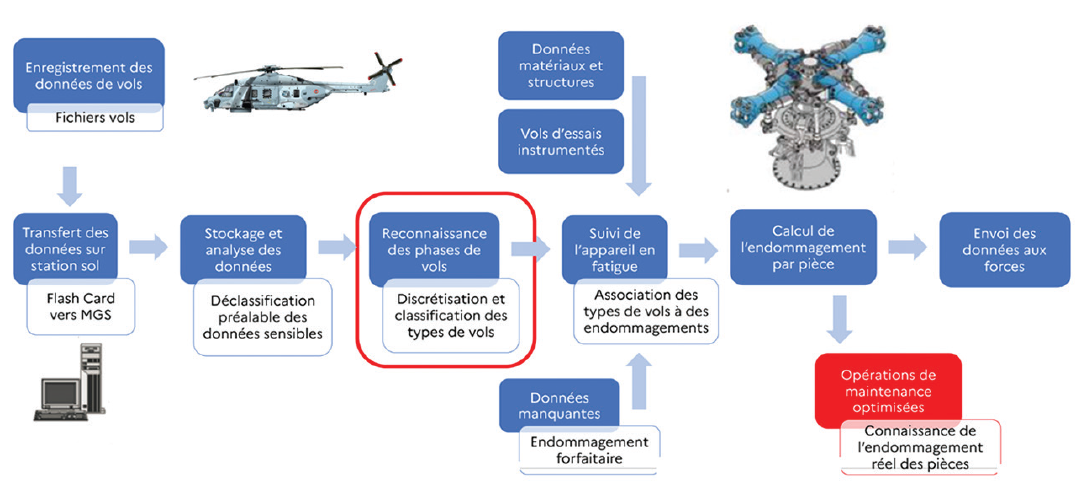
Fig.6 Principe du suivi en fatigue des hélicoptères (DGA TA)
L’IA est ainsi utilisée pour classifier les différentes phases de vol et associer à chacune d’elle un endommagement forfaitaire calculé au préalable. Une technique associant un réseau de neurones auto-encodeur (Variational Auto-Encoder) avec des k-voisins (k-NN) permet d’implémenter un classifieur. L’intérêt de cette approche est de permettre de suppléer aux données manquantes, voire de prédire un endommagement en l’absence de modèles ce qui est le cas sur certains avions anciens (par exemple les Canadair). Une des perspectives des travaux présentés concerne la reconstruction des spectres locaux de contrainte et déformation pour un calcul plus précis des endommagements.
La sixième intervention de la journée fut donnée par Michele Colombo (AIRBUS SAS), elle était intitulée « Prédiction de l’aéroélasticité dynamique de la rafale d’un HALE utilisant un réseau de neurones à graphe ». Les travaux rapportés en de très nombreuses occasions témoignent de l’intérêt considérable de la communauté charges/structures aérospatiales pour la construction de modèles de substitution (Multidisciplinary Design Optimization, Multi-Physics Computations) s’appuyant la plupart du temps sur des approches basées uniquement sur les données. Le cadre général de la présentation fut celui d’une utilisation plus marginale de l’IA pour l’apprentissage des systèmes dynamiques, reposant sur des méthodes s’appuyant en plus des données, sur la connaissance des lois physiques gouvernant leurs réponses. Parmi les méthodes d’apprentissage, les réseaux de neurones à graphe (GNN) ont pour but de décrire des systèmes composés de blocs en relation les uns avec les autres, et des exemples d’applications des GNN pour l’apprentissage de systèmes dynamiques ont été récemment publiés (DeepMind, 2018, systèmes de masses-ressorts ; Lemos, 2022, systèmes orbitaux). L’objectif des travaux présentés était d’appliquer la technique à l’apprentissage d’un modèle aéroélastique avion, avec à terme l’idée de l’utiliser pour prendre en compte les mesures et établir le lien avec toutes les mesures faites en vol.
Dans un réseau de neurones à graphe, l’information est encapsulée sous forme de variables associées au bord, au noeud ou au contexte global (grandeurs v, E, U sur la figure 2). Organisé autour d’un encodeur, d’un coeur de traitement et d’un décodeur, le GNN permet de travailler sur un espace latent (espace de représentation plus pertinent que l’espace des variables initiales). Dans le cas présenté, les variables physiques du problème d’aéroélasticité furent attribuées comme suit aux variables d’entrée [Noeuds(V) : Positions de noeuds, vitesses, masses ; Bords(E) : Caractéristiques structurales ; Global(U) : états de l’avion et vent de rafale] et de sortie [Noeuds(V’) : vitesses à t+1 ; Bords(E’) : Charges à l’instant t ; Sorties(U’) : dérivées] des graphes, autorisant une substitution rapide des charges de l’avion et de la dynamique de l’avion.
Chaque bloc contient un opérateur physique avec la possibilité d’une identification symbolique pour découvrir la nature mathématique des interactions. Le code original (de la littérature) fut adapté aux spécificités aéroélastiques. Des agrégateurs linéaires furent ajoutés pour couvrir le besoin d’une capacité théorique à observer la forme de l’avion avant le calcul de charge. Une structure dédiée d’encodage, traitement, décodage fut développée. Des tests sur un modèle jouet, puis sur le cas-test de Deep Mind furent réalisés avec de meilleurs résultats et une bonne capacité de prédiction à long terme. Le travail fut ensuite porté sur un HALE (High Altitude Long Endurance) UAV (Unmanned Aerial Vehicle) : cas universitaire SHARPy HALE en rafale longitudinale (1-cos). Soixante simulations furent effectuées pour l’apprentissage et la validation du modèle, avec 20% de partitionnement apprentissage/test sur l’intervalle de temps. Des réseaux de neurones très simples de 128 neurones à 2 couches complètement connectés furent utilisés. Une approche de type « perte à long terme » (Long-term loss) fut retenue pour la régularisation de l’apprentissage, celui-ci ne nécessitant au final que 30 minutes, l’inférence étant presque immédiate. Les résultats de l’approximation furent jugés très bons.
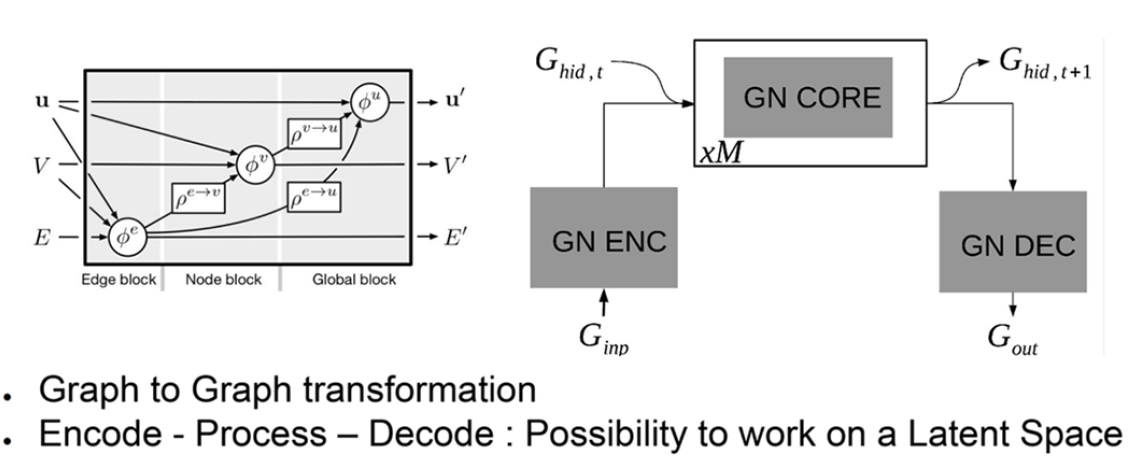
Fig.7 Architecture des réseaux de neurones à graphes (AIRBUS)
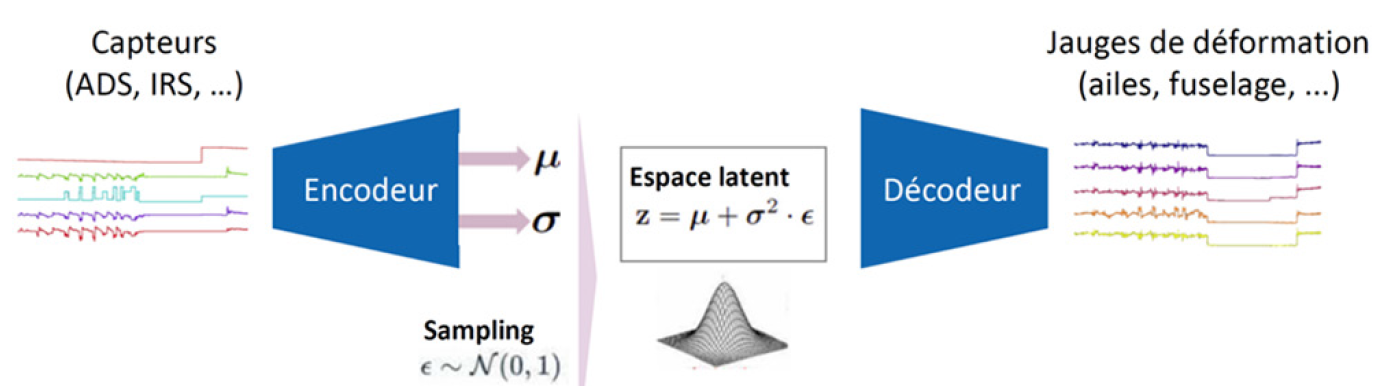
Fig.8 Architecture retenue par le gagnant du challenge Dassault-Aviation
En conclusion, le travail présenté concernait l’adaptation des GNN aux problèmes d’aéroélasticité, adaptation ayant mené à de bons résultats sur le calcul de charges. Une approche de type « perte à long terme » étant implémentée pour la dynamique aéroélastique, les résultats furent obtenus en mode autorégressif, avec les limitations bien connues des réseaux multi-couches pris comme approximateurs universels. Les pistes d’amélioration envisagées concernent le remplacement du réseau de neurone par des neural ODE (Ordinary Differential Equations), le recours à de l’identification symbolique, et la confrontation à un système réel ou à d’autres simulations. Concernant les neural ODE, l’utilisation d’un solveur d’ODE sur une fonction modélisée avec un réseau de neurone est envisagée : l’adaptation des NODE au cas graphe avec une entrée contrôle a déjà été explorée avec un partage entre graphe statique et dynamique, et a donné de bons résultats préliminaires.
Le septième exposé de la journée, intitulé « Instrumentation virtuelle des avions clients par apprentissage », fut effectué par Stéphane Nachar (DASSAULT AVIATION). Son objectif était de présenter comment Dassault Aviation développe un système lui permettant de calculer l’endommagement réel des structures des avions clients sur la base de mesures opérationnelles. Depuis la journée 3AF de 2017 “Le Big Data et ses opportunités d’application dans le domaine de l’aérostructure des avions d’affaires”, la science des données chez Dassault Aviation s’est déployée avec des applications multiples liées à une meilleure connaissance des statistiques d’utilisation, des critères de dimensionnement, de l’ambiance vibratoire, de l’impact climatique… Des collaborations furent initiées au travers de thèses sur l’ambiance vibratoire et le pronostic de pannes.
Le sujet de la présentation concernait l’instrumentation virtuelle des avions d’affaires, visant à s’affranchir de l’installation de jauges physiques sur avion, en les simulant grâce à des modèles d’apprentissage machine, les modèles étant entraînés sur des données d’essais sur avion équipé (perches, jauges…). Le but est ici de prédire, à partir des paramètres du vol mesurés par des capteurs fonctionnels (ADS, IRS, gouvernes…), les états de contrainte et de déformation en des points spécifiques d’intérêt.
Dans ce cadre, un challenge fut proposé par Dassault Aviation à plus de 35 candidats, challenge remporté par un consortium réunissant la start-up Aquila Data Enabler et l’ISAE SupMeca. Leur solution d’apprentissage reposait sur un schéma classique d’analyse : création des jeux de données, élimination des anomalies, régression, validation, déploiement du modèle. On utilisait des données temporelles et il était nécessaire de détecter les défaillances de capteurs. Un tableau de bord dynamique était utilisé pour la validation des experts métiers. L’architecture retenue s’appuyait sur un auto-encodeur variationnel (VAE). Un réseau de neurones fut utilisé car plus adapté à la dynamique multivariée des séries temporelles et à la détection des anomalies.
Sachant que le modèle allait mal généraliser sur les points qui contiendraient des anomalies, il convenait donc d’écarter ces points. Deux types de métriques furent utilisées pour la généralisation : erreur de reconstruction et vraisemblance des vecteurs latents. En effet, il est possible de distinguer les anomalies par des visualisations 2D (projection par composante principale ou t-SNE) : les anomalies apparaissant comme des clusters éloignés dans l’espace latent. Par ailleurs, une quantification de l’incertitude des prédictions à l’aide d’une régression de quantile, est possible, ce qui permet de donner des intervalles de confiance sur la prédiction. Finalement, un tableau de bord permettait d’apprécier la qualité des résultats : les erreurs, suivant différentes métriques, présentées par vol. Les résultats s’avérèrent très bons et souvent meilleurs que les résultats des modèles physiques. En plus de la prédiction, le modèle pouvait aussi être utilisé pour détecter les anomalies (ou points d’étonnement) à partir d’un score de normalité, ce score s’appuyant sur la probabilité de reconstruction dans l’espace latent. On pouvait aussi analyser la corrélation entre différentes familles de capteurs.
En résumé, un modèle adapté à la prévision mais aussi à la détection d’anomalies a été développé. Il permet de prédire les cycles de déformation de l’appareil, associés à des intervalles de confiance. L’analyse de l’espace latent peut amener une forme d’explicabilité supplémentaire. Le modèle est adapté pour de l’hybridation avec la physique (travaux en cours sur les ODE-RNN). L’inférence est instantanée et il y a un faible temps d’apprentissage. Aquila propose des cadres généraux, qui aident à la construction de ces modèles.
En termes de conclusions et perspectives, les prédictions furent obtenues avec une précision jugée suffisante. La prochaine étape s’intéressera au calcul de l’endommagement par les outils de simulation classiques. D’autres cas d’usage sont envisageables pour les capteurs virtuels : amélioration de la surveillance des vols d’ouverture de domaine, détection d’anomalies sur la chaîne de mesure ou d’acquisition, détection de signes avant-coureur de panne sur les systèmes. Peuvent également être envisagées comme perspectives, l’hybridation entre modèles physiques et modèles appris sur les données, ou encore l’apprentissage frugal appliqué à la génération de modèles de turbulence, à la CAO générative…
La huitième et avant-dernière présentation de la journée était intitulée « Conception de la structure d’une automobile par simulation 3D, apport de la data science », par Yves Tourbier (RENAULT). Le but de l’exposé était d’expliquer comment Renault utilise la science des données pour construire des modèles les plus frugaux possibles pour mener ses études d’optimisation de conception en crash d’automobile avec un minimum d’analyses. Les travaux présentés relevaient de l’optimisation numérique et de la réduction des modèles exploitant la science des données. Ils ont été mis au point et testés principalement en crash mais aussi en acoustique, combustion et aérodynamique véhicule.
Une contrainte imposée à l’exercice d’optimisation des projets véhicules est qu’il doit utiliser le même modèle qu’en simulation (conception, validation) : on peut utiliser un modèle simplifié pour chercher la solution, mais il faudra converger ou vérifier tout au moins avec le modèle complet que les résultats recherchés sont atteints. Les paramètres à considérer sont les épaisseurs, matériaux des pièces, formes, le nombre et la position des points de soudure, la présence/absence de renforts : on en compte plusieurs dizaines pour chaque cas d’étude. Pour traiter ses problèmes d’optimisation, RENAULT utilise la méthode des plans d’expériences, avec un coût en nombre de simulations 3D de 3 à 10 fois le nombre de paramètres, et des durées d’études de 2 à 4 semaines. Les méthodes plus automatiques testées, comme EGO (Efficient Global Optimization) donnent des coûts de 10 à 20 simulations par paramètre, ce qui est trop lourd : d’où la recherche d’une nouvelle méthode d’optimisation (où le nombre de calcul crash serait proche du nombre de paramètres de conception) qui permettrait de réduire le coût et le délai des études d’optimisation pour faire face à l’évolution des modèles (de plus en plus gros), de la demande en optimisation, et à l’élargissement des études en nombre de paramètres.
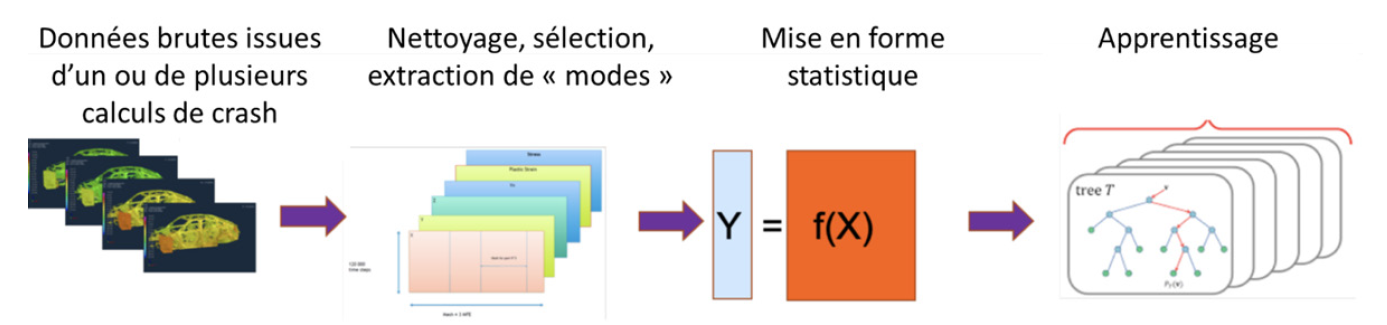
Fig.9 Principe de la méthode ReCUR employée chez RENAULT
Quelques chiffres : un modèle de crash, c’est 6 à 10 millions d’éléments finis, 120.000 à 200.000 pas de temps, 20 observables par noeud (20 champs). On travaille en pratique sur 200 pas de temps et on restreint les champs à des points d’intérêt. Les pistes de recherche qui visent à réduire le coût individuel des calculs, à disposer d’un modèle réduit intrusif, à profiter des études passées (transfer learning) ou à utiliser des modèles multi-fidélités sont jugées difficiles. La méthode de Régression-CUR, un modèle réduit non intrusif profitant de la définition particulière des paramètres, a été privilégiée. Elle consiste d’abord à séparer les variables de temps et d’espace pour chaque champ, comme c’est généralement le cas des méthodes ROM (e.g. POD), mais Régression-CUR impose d’employer une méthode de réduction permettant de remonter aux paramètres de conception. Pour ce faire, la méthode EIM a été retenue car elle sélectionne des pas de temps et des noeuds du maillage, ce qui permet de remonter aux paramètres de conception. Les techniques sont les mêmes que dans les méthodes ROM classiques : chaque champ M est décomposé par M=CUR avec R matrice des modes temporels, C matrice des modes spatiaux et U la matrice des coefficients. Ces modes sont ensuite utilisés pour construire un problème de régression. Chaque mode ou couple de modes temps x espace correspond à une colonne dans la matrice de régression X. C’est la partie construction des caractéristiques ou « features ». La méthode « Random Forest » est ensuite utilisée pour prédire la réponse Y.
Le principe de construction des colonnes de X repose sur le mélange des paramètres d’optimisation et des paramètres de champs, en profitant du fait que les paramètres ont une définition globale (l’épaisseur d’une pièce) mais aussi locale (les noeuds du maillage de la pièce héritent de l’épaisseur de cette pièce). Les modes étant des sélections dans les champs, ils héritent aussi des valeurs des paramètres de conception. Ceci permet d’intégrer dans le modèle de régression à la fois la simulation par les paramètres de champs et l’optimisation par les paramètres de conception. On peut rajouter des paramètres supplémentaires qui ne sont pas liés à des noeuds du maillage comme des points de soudure. La notion de noeud permet de réduire le nombre de paramètres : on passe d’un ensemble de paramètres d’épaisseur des pièces à un seul paramètre d’épaisseur du noeud de maillage. Cependant il peut y avoir des discontinuités dans les prédictions car des noeuds proches peuvent appartenir à des pièces différentes.
Un exemple d’étude en choc arrière avec contrôle de critères sur le réservoir fut présenté. L’idée était de corriger des critères non satisfaits avec un minimum de pénalité de masse. NB : le calcul crash n’est pas parfaitement répétable (instabilités dans le calcul physique comme le flambement, ou purement numériques). Étaient utilisés deux modèles réduits, un pour le nominal (sur la moyenne), l’autre pour la dispersion.
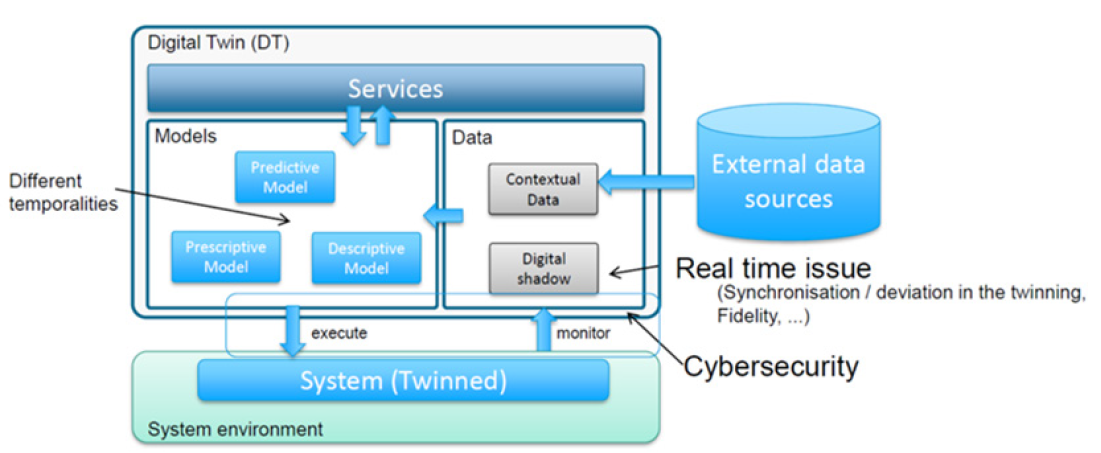
Fig.10 Schéma de principe du jumeau numérique (cf document IRT-SystemX/JNI3)
L’optimisation se faisait en deux étapes et une solution satisfaisante fut finalement obtenue, avec un ajout limité de 4kg.
En termes de conclusions et de perspectives, la méthode ReCUR présentée permet de réaliser des études industrielles à moindre coût. L’outil est en cours d’industrialisation par ESI (code PAMCRASH). La DEIM (Empirical Interpolation Method) ne s’avère finalement pas si adaptée à l’étude du crash (trop de modes). Une évolution vers les réseaux de neurone est envisagée, ainsi que l’intégration de contraintes supplémentaires, du type conservation de l’énergie totale (PINN), le tout associé à du Transfert Learning pour exploiter les résultats des études précédentes.
La dernière présentation de la journée, intitulée « Construire les premières étapes du jumeau numérique du moteur de demain », fut faite par Dohy Hong (SAFRAN Tech). L’objectif de l’exposé était de présenter ce qu’est le jumeau numérique pour SAFRAN Tech et quels en sont les principaux enjeux, sachant que l’objectif est d’abord de prédire le vieillissement des structures dans le temps, mais aussi d’améliorer le dimensionnement de celles-ci vis à vis des nouveaux enjeux écologiques.
Une vue d’ensemble de la problématique chez SAFRAN-Tech fut d’abord présentée : le jumeau numérique repose sur un modèle numérique, et peut se décliner selon 3 modes, par : (1) utilisation combinée d’apprentissage machine et de modèles physiques, (2) fusion de données mixant données expérimentales et de simulation, et mélange de modèles, ou (3) approches physiquement informées, tenant compte de la description géométrique, des équations mais aussi du retour d’expérience pour intégrer des corrélations par exemple.
Sa mise en oeuvre nécessite les 3 ingrédients que sont, le système réel (instrumenté), le modèle digital, et les données (issues de l’instrumentation et du modèle). Différents jumeaux numériques spécifiques sont construits selon le contexte (conception – production – opération) avec ces 3 ingrédients. Chez SAFRAN-TECH ces jumeaux numériques doivent être inter-opérables. Le jumeau numérique propose des services interagissant avec des données, et des modèles qui sont respectivement monitorés et exploités par le système réel jumelé. Les données sont traitées en temps réel et constituent l’ombre numérique (digital shadow) du produit. Il peut aussi y avoir un besoin de données externes au système.
Concrètement, Le problème est ici formalisé comme un filtre de Kalman (offrant un cadre naturel pour quantifier les incertitudes) avec deux lois : une loi de transition (comportement) et une loi de données (mesures). L’effort d’apprentissage porte sur la loi de transition et doit tirer parti en plus de l’intuition, des hypothèses, des connaissances physiques. Sont aussi utilisés des filtres à particules basés sur des échantillonnages pondérés.
La viabilité et l’opérationnalité du jumeau numérique reposent sur les 3 pré-requis/principes que sont : (1) la continuité digitale permettant d’assurer la traçabilité des données, tout au long du cycle de vie du produit, (2) la représentativité du clone numérique, qui reproduit le fonctionnement du système et en particulier son vieillissement, et (3) la capacité d’estimation de l’état de santé, à partir des données historiques. C’est sur cet aspect que porte l’effort de SAFRAN.
Le premier défi technique auquel l’objet jumeau numérique est confronté – lorsque l’application visée (court terme) concerne la recherche de signatures (anomalies, ruptures, tendances), le diagnostic (solution de pannes en maintenance) ou le pronostic (planning de production) - concerne la grande diversité des sources de données qui sont à traiter, données d’opération (en enregistrement continu : QAR, équivalent boite noire), données « shop », données « bench », … Les modèles développés reposent sur des approches agnostiques, avec de l’apprentissage machine, mais peuvent utiliser des approches physiquement informées (PIML) pour cibler la recherche, en particulier la sélection des variables (features) et assurer un niveau d’interprétabilité. Le second défi est lié à la problématique la dégradation progressive de l’ensemble du système sur temps plus long, l’étude du vieillissement nécessitant des représentations en modèles réduits (température par exemple), au regard de la quantité d’informations à stocker/à interpréter. Enfin, les clones numériques individualisés représentent un défi pour la continuité numérique, et pour le recours à l’intelligence artificielle : il est en effet nécessaire de tirer parti de la donnée à tous les stades, conception (données test bench), réception et opérations (données de vol et de configuration), inspection, et maintenance.
Pour conclure, le jumeau numérique pour SAFRAN est un moyen de mieux identifier l’état d’un système et labelliser les données. Il permet des gains dans la simulation du système, la résolution de problème et la réduction des coûts de maintenance. Un sujet de réflexion important pour SAFRAN est également mentionné, qui concerne l’ouverture des données au-delà de l’enceinte de l’entreprise : comment partager un jumeau numérique avec des partenaires extérieurs ? Une coopération avec l’IRT SystemX est en cours pour le développement d’un cadre commun pour la construction de jumeaux numériques. Des travaux sur les jumeaux numériques de batteries ou de trains d’atterrissage sont également évoqués.
TABLE RONDE
(animée par Pierre Ladeveze, Francisco Chinesta et Stéphane Grihon) et conclusion de la journée
Preuve de l’actualité et de la vivacité du sujet, mention fut faite au cours de la journée de nombreux projets industriels et de recherche sur les sujets traités en séance (certains en collaboration internationale, comme avec Singapour, au sein de l’EUROCAE, de l’ASME, …), du campus d’excellence CREATE, avec des centaines de chercheurs et de nombreux industriels impliqués, d’un Groupement de Recherche (GDR) créé en Janvier 2023 pour travailler sur la simulation augmentée par la donnée et l’apprentissage automatique (GAIA), etc. Avec une audience de près de 80 participants, répartis entre les sites parisiens de SAFRAN-Tech et toulousain d’AIRBUS-SAS, de très nombreuses questions générales ou techniques purent être posées, dans la foulée des exposés ou lors de la table ronde qui clôtura la journée, et les échanges – qu’il n’est pas possible de relater dans leur entièreté dans cette synthèse - allèrent bon train. Tous de s’accorder sur le fait que le champ très large des applications potentielles et la puissance de ces méthodes, repoussent les limites du « solutionnable », et ouvrent la voie au traitement de nouvelles problématiques, qui vont à leur tour amener de nouveau concepteurs et chercheurs à challenger leurs connaissances, ainsi que les capacités technologiques émergentes les plus puissantes. Des approfondissements thématiques furent à ce titre suggérés, par exemple sur les sujets suivants : (1) jumeau numérique, maturité, verrous, unicité ou diversité, (2) gestion de l’incertain, statut sur l’implémentation industrielle, difficultés et solutions, (3) sûreté des modèles basés sur la donnée et certification. Ce qui donnera lieu nous l’espérons à de futurs échanges entre participants, de façons plus spécifiques.
REMERCIEMENTS
3AF tient à remercier de nouveau les orateurs qui – en partageant leur expertise - ont permis la tenue de cette journée scientifique et technique, ainsi que les organisateurs SAFRAN-TECH et AIRBUS-SAS, qui ont accueilli les participants dans leurs locaux.





Aucun commentaire
Vous devez être connecté pour laisser un commentaire. Connectez-vous.